任务背景
将结果写在最前面:复现失败,因为32G V100显卡还是显存不足,但环境搭建基本成功。本文是旨在总结使用计算集群、开源包,搭建运行环境的经验贴
PS: 日志文件截图(显存不足)

ONE-PEACE是截至目前(2023/10/1),在ADE20K数据集上做语义分割任务SOTA表现的模型(详见[Papers With Code](ADE20K Benchmark (Semantic Segmentation) | Papers With Code)),本次任务为复现ONE-PEACE模型的表现(基本不可能,因为原论文的结果是8块80G A100显卡跑出来的,算力差距大)
目前可用资源是 1)Linux主机:GPU配置为2× 24G GTX 3090显卡;2)北邮(BUPT)超算平台提供的GPU计算节点,共3个GPU节点,每个节点多块Tesla V100 32G显卡,搭配OPA卡实现节点间高速通信
如何应对GPU显存不足的现状
明确一个观点,任何trick都无法逾越算力差距的鸿沟(比如:本任务我们只有32G和24G两种显卡,论文的实验用到了80G A100),我们需要做的是尽可能的降低算力需求,即便今天我们做不出实验,但当下的尝试可以为未来的实验积累经验
本次实验使用的两个小trick -> 降低显存占用:
with_cp参数:共享内存的手段,已经内置在mmcv包中,只需要config文件中,设置该bool型参数为True即可降低输入图片的分辨率(from issue #22)
由于80G A100显卡硬件资源难得,作者提出可以将输入图像分辨率从
896×896降至512×512。相应的,config文件中有需要与输入分辨率同时变化的条件 –bucket_size(用来计算相对位置编码,必须能被input_resolution整除),需要从56降至32
使用计算集群(北邮超算中心)部署模型
写在前面,本次实验失败最大的问题就在于对做实验的工作流还是不够清晰。当拿到一个计算资源要求极高的试验任务,最大的前提是实验的可行性。应该先租一个单卡V100,将运用trick的模型部署尝试一下,如果单卡跑不了,分布式也救不了
计算集群相关知识
- 面向本次任务,最重要的知识点就是Singularity容器化技术+Conda虚拟环境
- Singularity容器化技术
- 容器化技术的核心是:创建一个移植性好,使用便捷的镜像文件,简化安装包管理和兼容性问题。同时,可以与主机共享操作系统内核,保证了功能强大。
- Singularity 1) 专注于科学计算工作负载和HPC(高性能计算)环境。2) 它借助Linux环境下的用户命名空间和挂载功能,使得容器中的应用程序可以以与主机系统几乎相同的方式运行。
- Singularity和Docker技术的不同
- Singularity可以在各个用户权限下使用,Docker需要root权限,灵活且安全,因为Singularity借用了主机上的用户命名空间,同时利用Linux的用户命名空间功能进行隔离。这种权限控制使得Singularity容器更加安全,避免了一些特权升级的风险
- Singularity容器可以与集群的资源管理系统(如Slurm、PBS等)无缝集成,HPC集群通常具有严格的资源管理和调度机制。Docker则不可以
- Singularity可以访问HPC专门设置的高性能互联网络(eg. OPA卡),而Docker容器使用的是主机上的标准网络接口,无法直接访问高性能互连网络。
- Conda虚拟环境:将在下一部分”搭建环境遇到的问题”中,
MultiScaleDeformableAttention编译问题中讲解—-为什么要在容器的基础上加入Conda虚拟环境
- Singularity容器化技术
- 使用计算集群的三个层次:
- 在用户目录下:用户目录下,一般没有cuda和GPU。需要准备好项目文件和需要的预训练模型,因为Singularity容器与主机使用同一套文件目录,所以不会出问题(Docker就需要把文件放入Docker的工作目录)
- 在容器环境内:使用
singularity shell <容器名>进入容器,此时有了cuda,可以nvcc -V查看cuda版本号。需要在容器中安装包和依赖,方便开箱即用 - 进入计算队列:排上队之后,硬件资源分配好之后,可以使用GPU和cuda,通常是预写好一个脚本,包括进入虚拟环境,进行需要GPU的模块的编译,包的安装,和训练脚本的执行
- 面向本次任务,最重要的知识点就是Singularity容器化技术+Conda虚拟环境
搭建环境遇到的问题
基础Singularity镜像(创建Singularity容器比较简单)
Python 3.8
cuda 11.3
Pytorch 1.11.0+cu113
opencv安装问题:(在容器环境中安装)
问题:缺少依赖库
解决方案:配置文件
requirements.txt中,要求安装opencv-python模块,有GUI模块,所以要安装相同版本的无GUI模块的opencv-python-headlessMultiScaleDeformableAttention编译问题(在进入计算队列后编译,因为编译需要GPU)
问题:导入包失败 -> 编译包失败
编译时的报错如下:
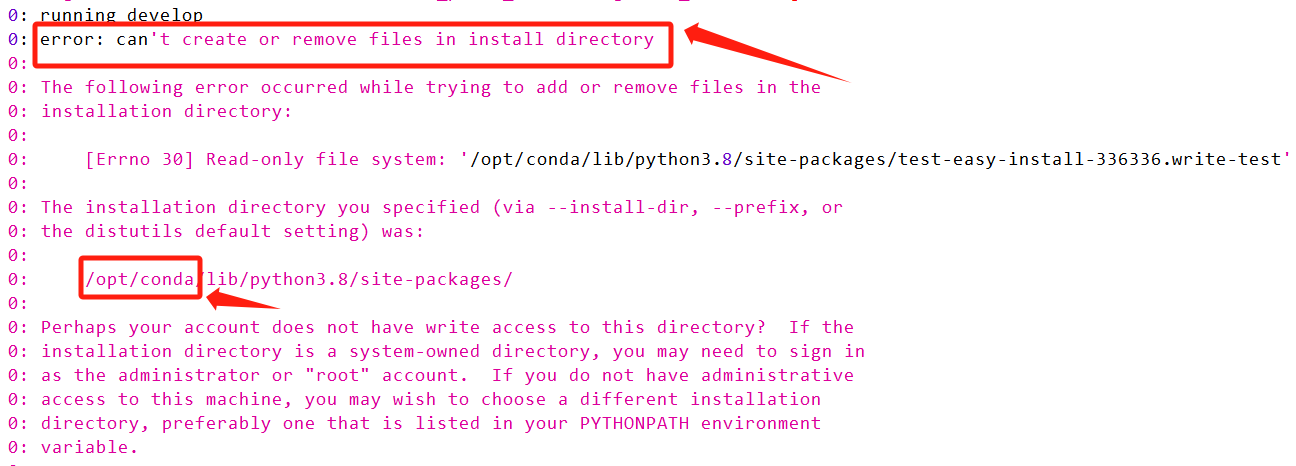
从报错可以看出:问题处在我们使用的Python是
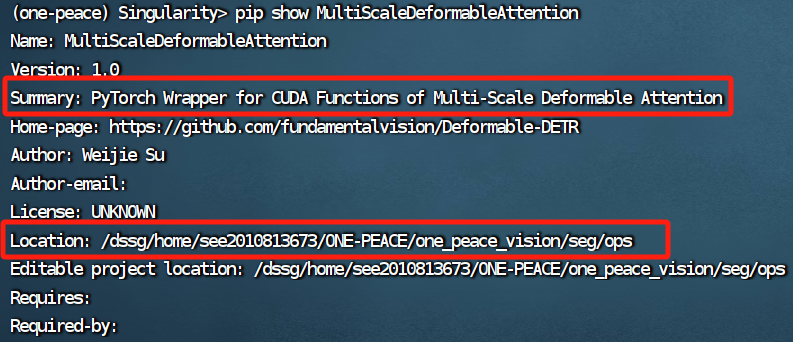
/opt/conda下的,由于没有root权限,无法写入主目录。而正在编译的MultiScaleDeformableAttention模块是多尺度可变形注意力模块的cuda支持,编译成功会产生.so文件,也需要将链接写入目前使用的Python的site-packages。解决方案:在Singularity容器中使用Conda虚拟环境。Singularity容器中默认使用的还是/opt/conda下的,但使用Conda创建虚拟环境,就需要找到用户权限的Conda并使用,所以我们创建虚拟环境后(此时使用的是用户的Conda),重新安装基础环境,只要在提交计算任务时,使用的脚本里
source activate <虚拟环境>,就可以将MultiScaleDeformableAttention模块安装在有权限写入的python3.8/site-packages目录中最后的效果:
MMCV包安装的环境问题

分析问题:cuda:0上关于
ms_deform_attn_impl_forward的实现没有找到,这个模块是和MultiScaleDeformableAttention相呼应的,因为使用的可变形的注意力模块,所以必须在有cuda和GPU的情况下,安装MMCV包。观察日志,如下图,MMCV确实没有在cuda下编译:
改变的方法:将MMCV包的安装写在提交任务,执行的脚本中,在有GPU环境下重新安装包
最后的shell脚本:
