9/22 - curl
curl是利用URL语法的网络请求工具,支持HTTP, HTTPS, FTP等协议
HTTP和HTTPS
HTTPS全称为
Hypertext Transfer Protocol Secure, 与 HTTP 协议相比,HTTPS 协议在通信过程中引入了SSL/TLS 协议来实现安全传输。SSL/TLS 协议使用公钥加密和私钥解密的算法,对传输的数据进行加密,同时使用数字证书对服务器的身份进行认证。这样可以确保客户端和服务器之间的通信安全和可靠。PS: 我们在URL中看到
https://或者http://, 它被称为 URL 的协议头(scheme),表示使用的协议类型。URL的协议类型还包括(FTP, SMTP, POP3, IMAP, ssh, Telnet, DNS, JDBC),但不是每一个协议头都可以通过curl直接拉取对应URL的内容(eg:curl smtp://smtp.gmail.com-> 发出GET请求,无法直接获取到目标服务器的内容,而是返回了服务器的响应信息)HTTP常见请求
curl <URL>(默认发出GET请求)curl -XPOST <URL> -d "需要嵌入的data"(-X指定了发出的http请求的方式是POST, 有两种写法:-X POST或者-XPOST)GET & POST & PUT & DELETE
四种http请求方式
- GET:用于请求获取指定资源的信息。通过 GET 方法发送的请求,服务器将返回请求的资源。
- POST:用于在服务器上创建新的资源。通过 POST 方法发送的请求,服务器将根据请求中的数据创建新的资源,并返回相应的信息。
- PUT:用于更新指定资源的信息。通过 PUT 方法发送的请求,服务器将使用请求中的数据更新指定的资源。
- DELETE:用于删除指定的资源。通过 DELETE 方法发送的请求,服务器将删除指定的资源。
HTTP首部
curl <URL> -H 首部(可以自定义HTTP请求的首部,格式为:-H “字段名: 值”,可以修改多个字段,只需要使用多个-H即可)curl -I <URL>获得响应的所有首部的信息HTTP首部
HTTP 首部可以分为两类:请求首部和响应首部。下面是一些常见的 HTTP 首部示例:
请求首部:
Host:指定要访问的服务器主机名和端口号。User-Agent:标识发起请求的用户代理(如浏览器、爬虫等)。Content-Type:指定请求体的媒体类型。Authorization:提供对资源的访问授权凭证。
响应首部:
Content-Type:指定响应体的媒体类型。Content-Length:指定响应体的长度。Set-Cookie:在响应中设置一个 Cookie。Location:指示客户端重定向到的 URL。
此外,还有一些其他重要的首部,如
Cache-Control、ETag、Last-Modified等,用于缓存控制和条件请求。文件下载
curl -O <URL>(正常下载)curl -o 文件名 <URL>(下载到特定文件内)curl --limit-rate 速度 <URL>(下载大文件需要控制下载速度,如果下载被中断,使用curl -C - <URL>可以恢复下载)连接与测试
curl -L <URL>(curl默认不会跟随重定向,所以要有些网站无法访问,-L解决问题)curl -v <URL>(将连接时候的握手信息,请求和响应的首部信息打印出来,可以看哪里出错)curl --proxy 协议头://用户名:密码@代理地址:端口 <URL>FTP相关
curl -u 用户名:密码 -O ftp://server/...(认证+下载)curl -u 用户名:密码 -o 文件名 ftp://server/...curl -u 用户名:密码 -T 文件名 ftp://server/...(认证+上传)FTP
FTP有
主动模式与被动模式主动模式: FTP 客户端(通常是本地计算机)发起与 FTP 服务器的连接。客户端随机选择一个未使用的本地端口(N>1023),并通过这个端口与服务器的控制端口(通常是端口 21)建立连接。然后,客户端通过控制连接发送 PORT 命令,其中包含了客户端数据连接的 IP 地址和端口号。服务器从该指定的数据端口向客户端的数据端口发起连接,进行数据传输。(curl使用FTP传输默认为主动模式,curl -P 端口可以指定端口)被动模式: 在被动模式下,FTP 客户端发起与 FTP 服务器的连接。客户端通过控制连接发送 PASV 命令,服务器在一个指定的非特权端口(通常是端口号大于 1023)上监听连接。然后,服务器将其 IP 地址和监听的数据端口号作为响应发送给客户端。客户端随后通过数据连接的新端口与服务器的数据端口建立连接,并进行数据传输。(curl --ftp-pasv且不使用-P和--ftp-port可以切换到被动模式)
9/23 - iptables
流量进入过程:->网卡->Linux内核(过滤流量 -
netfilter负责)->网络谣言(用户空间)iptables: 普通用户通过iptables(前端)操作netfileter(后端),可以类比为用户自定义的防火墙配置tables:
filter,nat,mangle,raw,security(前两个最重要)filter: 过滤nat: 网络地址转换,还可以负载均衡filter在内核和硬件/用户空间的交互中,有五条链路:
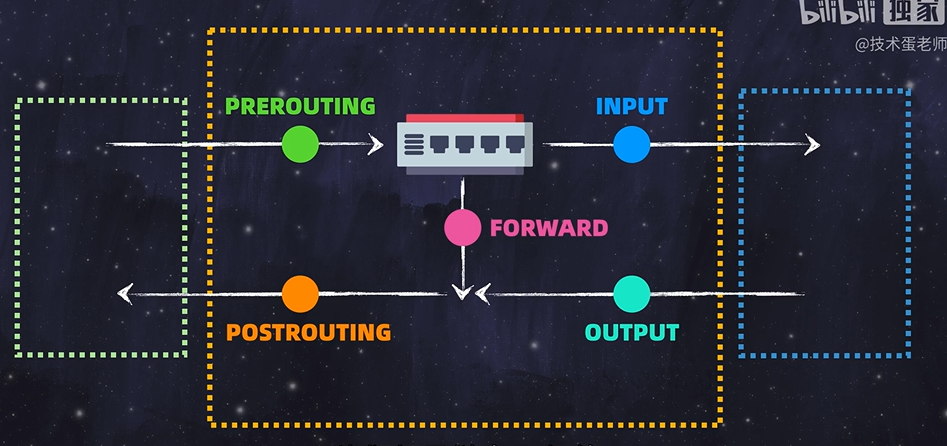
当使用
filter表时,需要管理INPUT,OUTPUT,FORWARD链sudo iptables --table filter --list (--line-numbers): 查看filter表的链路以及链路上的规则sudo iptables --append(-A) 链名 --source(-s) 源ip(/子网掩码) -p 协议 -d 目标ip(/子网掩码) --jump(-j) REJECT/ACCEPT/DROP: 制定规则,此时无需指定–tables,因为filter是管理链路的接口,而我们是直接指定链路上的规则(常用的扩展选项:–dport 指定端口)sudo iptables --table filter --delete INPUT 1: 通过filter表,删除INPUT链路中的第一条规则(在表中对应为行号为1的规则)sudo iptables -F INPUT: 清空input链中的所有规则。用
ipset优雅的批处理ip地址ipset create 集合名 hash:net: 创建空集合ipset list 集合名: 检查已有的ipset(Members字段显示集合中的ip地址)写脚本将有大量ip地址的文件传给
ipset,并给iptables设置规则(下面的例子是在WSL上编写的shell脚本)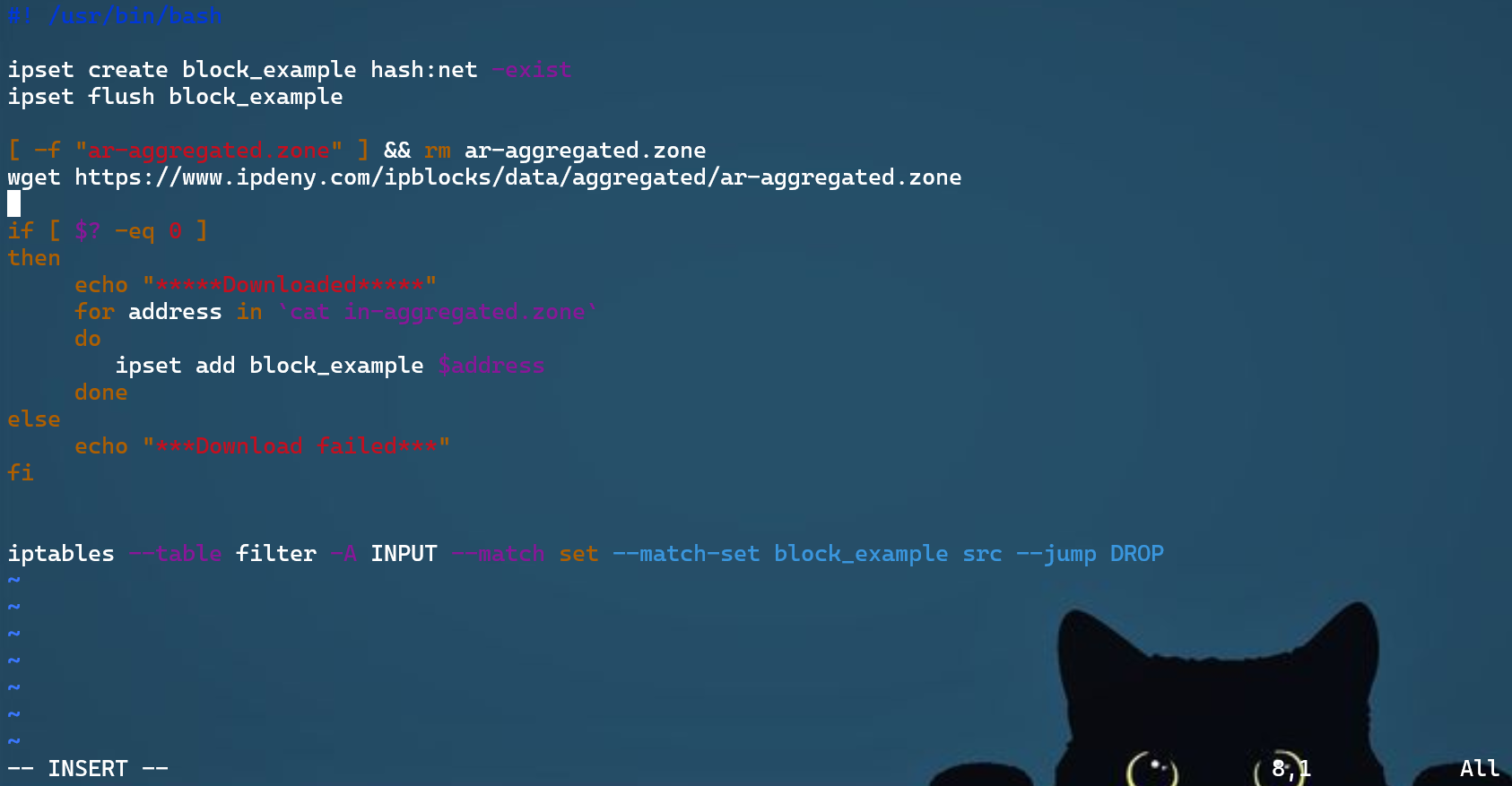
ipset和iptables在主机/服务器关机重启后,会被清空,所以设置好规则之后,需要
ipset save > /path/to/save/rules.ipsetiptables-save > /path/to/save/rules.iptables重启后,需要(这是不覆盖已有规则的方法)
ipset restore < /path/to/save/rules.ipset -existiptables restore < /path/to/save/rules.iptables --no-flush(-n)以下是一些常见的IP集合哈希表类型:
hash:ip:用于存储单个IP地址。hash:ip,port:用于存储IP地址和端口号的组合。hash:net,net:用于存储IP网络之间的组合。hash:net,port:用于存储IP网络和端口号的组合。hash:ip,port,ip:用于存储两个IP地址和一个端口号的组合,通常用于NAT转换等应用。
9/24 echo
echo <text>输出到终端history + echo !<id>: 输出history第id个命令重定向:
> <file>: 从头开始写入file>> <file>: 在file中续写
9/25 awk
awk是一种强大的文本处理工具,可以用于提取、过滤、处理和格式化文本数据。它以行为单位(Record)读取输入文件,并按照指定的规则执行相应的操作awk options 'pattern { action } <file>'– 基本格式(pattern字段用于匹配文本)awk 'NR==3{print $0}' <file>–用pattern打印第三行(pattern和action中间可以没有空格)与不用模式的方法对比:
awk {if(NR==3) {print $0}}, 用pattern更简便只用
pattern,不用action:awk '/xm/' <file>,打印所有可以匹配到xm字段的record用
pattern打印第一行到第三行:awk 'NR==1, NR==3 {print $0}' <file>用
pattern打印第一行和第三行:awk 'NR==1 || NR==3 {print $0}' <file>awk '{print $1}' <file>– 打印每一行的第一列 (字段分隔符默认为空格) (print默认打印\n,printf不是)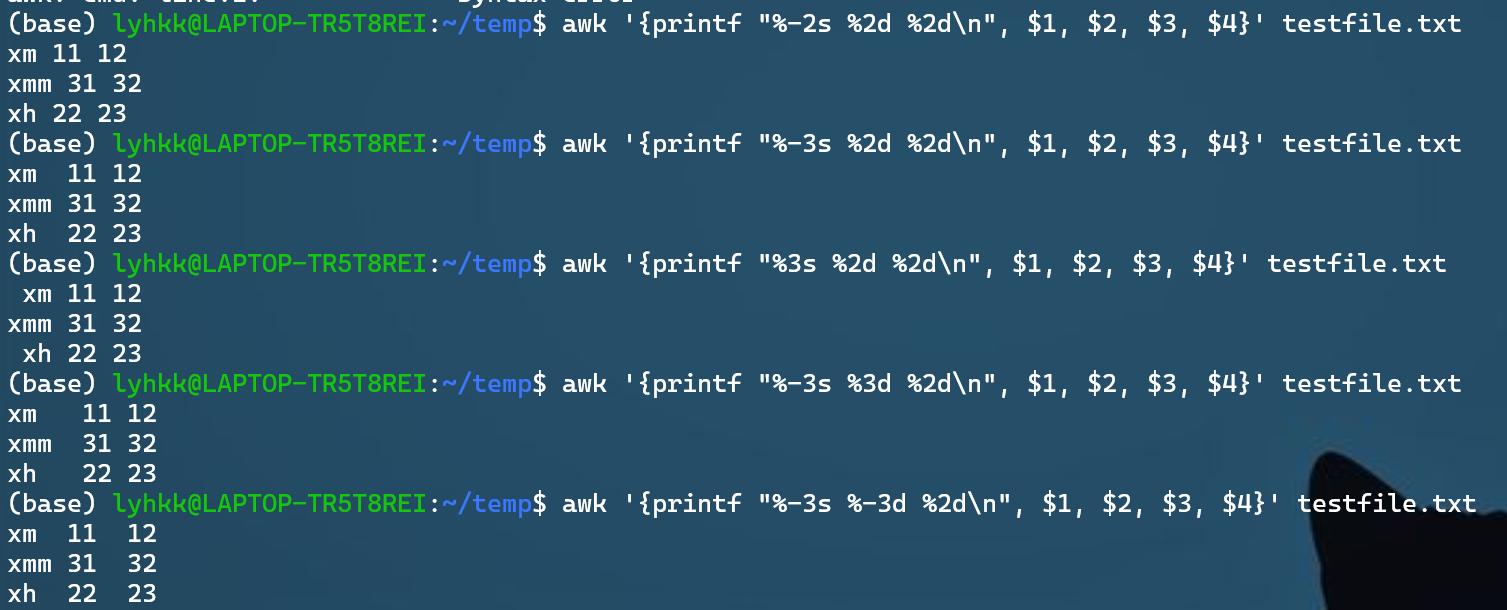
从上到下展示:(好像没有居中对齐)
- 没有对齐好的情况(%-2s)
- 第一列向左对齐(%-3s)
- 第一列向右对齐(%3s) —没有
-默认向右对齐 - 第二列向右对齐(%3d)
- 第二列向左对齐(%-3d)
常用option(option的参数最好也用单引号引起来)
-v var=value:, 赋值一个用户定义变量,将外部变量传递给awk,或者是设置内置变量
eg. 也可以外部引入,比方说打印环境变量:
awk -v var=$PATH 'BEGIN {print var}'-F: filed seperator,输入字段分隔符(示例如下图,
Command 1对应的是一个三行四列,文件中分隔符为,的情况;Command 2对应的是一个三行四列,文件中前2个字段分隔符为,,但第三个分隔符为空格的情况) -> ‘[]’允许不止一个分隔符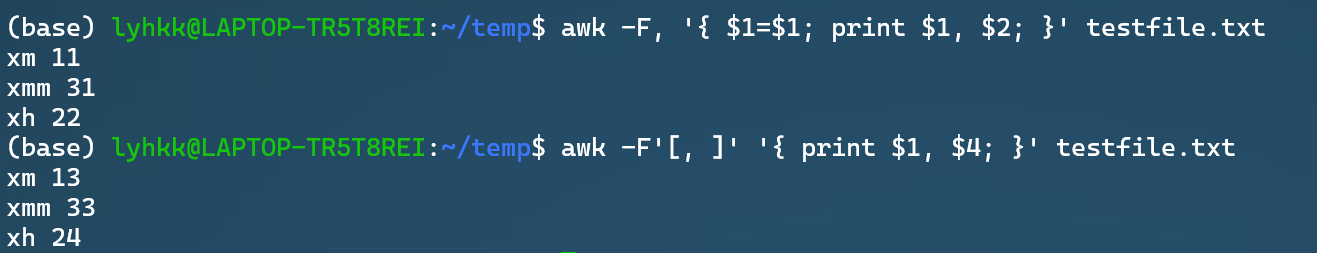
-f [写好的.sh]: 从脚本文件中读取awk语句块,脚本内不需要单引号
语句块
由
BEGIN或END或[pattern]或引领的语句,或者都没有pattern
/正则表达式/:使用通配符的扩展集。
eg. 打印有数字的Record(如果是
print $n, 就打印有数字的Record的第n列)awk '/[0-9]+/ { print $0; }' <file>(+是正则表达式中的 a+=a·a*的+,[]代表将[]内的内容变为字符类)关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试。
eg. 比较第一个字段是否大于 10。例如,可以使用
awk '$1 > 10 { print $0; }' <file>来打印第一个字段大于 10 的行。模式匹配表达式:用运算符~(匹配)和 ~!(不匹配)。
eg:
awk '$1 ~ /xm/ { print $0; }' testfile.txt
Attention: 表达式匹配有三种:以表达式
开头(/^expression/),结尾(/expression$/),或表达式存在于字段中(/expression/)BEGIN,END
对于命令
awk 'BEGIN{ commands } pattern{ commands } END{ commands }':- 首先执行
BEGIN {commands}内的语句块,注意这只会执行一次,经常用于变量初始化,头行打印一些表头信息,只会执行一次,在通过stdin读入数据前就被执行; - 从文件内容中读取一行,注意awk是以行为单位处理的,每读取一行使用
pattern{commands}循环处理 可以理解成一个for循环,这也是最重要的部分; - 最后执行
END{ commands },也是执行一次,在所有行处理完后执行,一帮用于打印一些统计结果。
内置变量
FS:字段分隔符(Field Separator),默认值是空格或制表符OFS:输出字段分隔符(Output Field Separator),默认值是空格RS:记录分隔符(Record Separator),默认值是换行符ORS:输出记录分隔符(Output Record Separator),默认值是换行符NF:当前记录中的字段数(Number of Fields),可以使用$NF获取最后一个字段NR:已读的记录数(Number of Records)$0:整个记录的文本内容$[n]:第n个字段(列), $这个符号自带循环属性,循环结是pattern{commands}语句块(文件的一个record),全部执行一遍后,进入下一条record(像下面的例子,先打印第1个record的$1$2$3)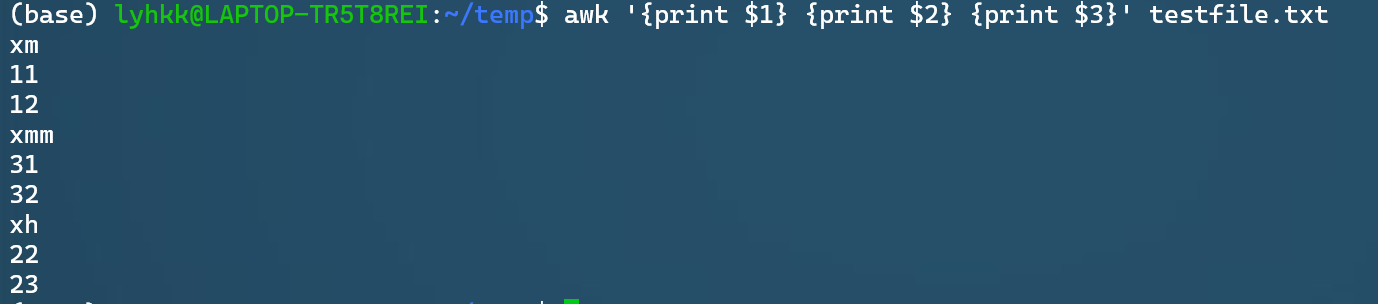
FILENAME:当前处理的文件名FNR:当前文件中已读的记录数ARGC:命令行参数的个数ARGV:命令行参数数组CONVFMT:数字转换格式(Conversion Format)
内置函数
9/26 ls
-l:以长格式(long format)显示文件和目录的详细信息,包括权限、所有者、大小、修改时间等 (ll是ls -l的缩写)-a:显示包括隐藏文件在内的所有文件和目录,包括以点开头的文件(通常被视为隐藏文件)-h:与-l配合使用时,以人类可读的格式显示文件和目录的大小,如使用 KB、MB、GB 等单位-r:反向排序,以相反的顺序显示文件和目录-t:按修改时间排序,最近修改的文件和目录排在前面-S:按文件大小排序,从大到小显示文件和目录-R:递归地列出目录及其子目录下的所有文件和目录--color:以不同颜色显示不同类型的文件和目录,增强可读性
9/27 find
查找文件
find <目录> -name "文件名/正则表达式(*.txt)": 这是严格区分大小写的查询,-iname不区分find <目录> -type f: 按照文件类型查找:f - 文本文件,d - 目录,l - 符号链接-user,-group: 支持按照用户或用户组的查找
9/28 cat
查看文件内容
cat -n 文件名 : 输出带行号
-b : 忽略空行,输出带行号
-s : 将文本间多个空行合并为一个
-E : 在每个换行的位置显示一个$占位符,这样防止一行过长,cat时的换行并不是文本的换行,空行会在一开始有$
-T : 将Tab以^I的格式显示出来,可以分辨是Tab还是空格
9/29 git(+Git Graph插件使用)
git 拉取远程私有仓库(参考博客)
工作流
在Github上生成个人token
在本地仓库目录下,执行
git clone https://user:<token>@ghproxy.com/<URL>user就是单词user,不是ID替换为个人访问令牌,令牌的格式是 ghp_xxxxx是完整的远程仓库地址(例:https://github.com/lyhkk/lyhkk.github.io.git) 为了长期的开发,需要配置
SSH key- 本地生成SSH密钥,将
~/.ssh/id_rsa.pub的内容(公钥)复制到Gothub上个人的SSH keys中即可
- 本地生成SSH密钥,将
git 多人共同开发(参考博客)
多人开发需要处理代码冲突问题,本地仓库是远程仓库的拷贝,但它的实时性无法保证,每一次
git pull就是为了更新最新版代码,并解决潜在的冲突(git merge)工作流
git commit(提交本地修改)- ->
git pull(拉取远程仓库的commit记录并与本地commit对比,注意不是和本地仓库代码直接对比,所以必须先commit,不然merge就无从谈起,只会导致本地仓库代码被远程仓库覆盖) - 沟通并确定好如何修改&&merge后,仍需要再次
git commit&&git pull&&git push,防止在双方协商时第三方更改代码,push失败
其它常见命令
git status:查看当前 Git 仓库的状态,并且是在本地仓库中运行的。它会告诉你已经修改/新增的文件、已经添加到暂存区的文件以及还未被 Git 跟踪的新文件等信息。git fetch:一种更安全温和的git pull,不会自动覆盖未commit的本地仓库修改,而是只检查远程仓库是否有新的提交或分支,并将这些信息下载到本地仓库中。git merge(内容来源为ChatGPT镜像)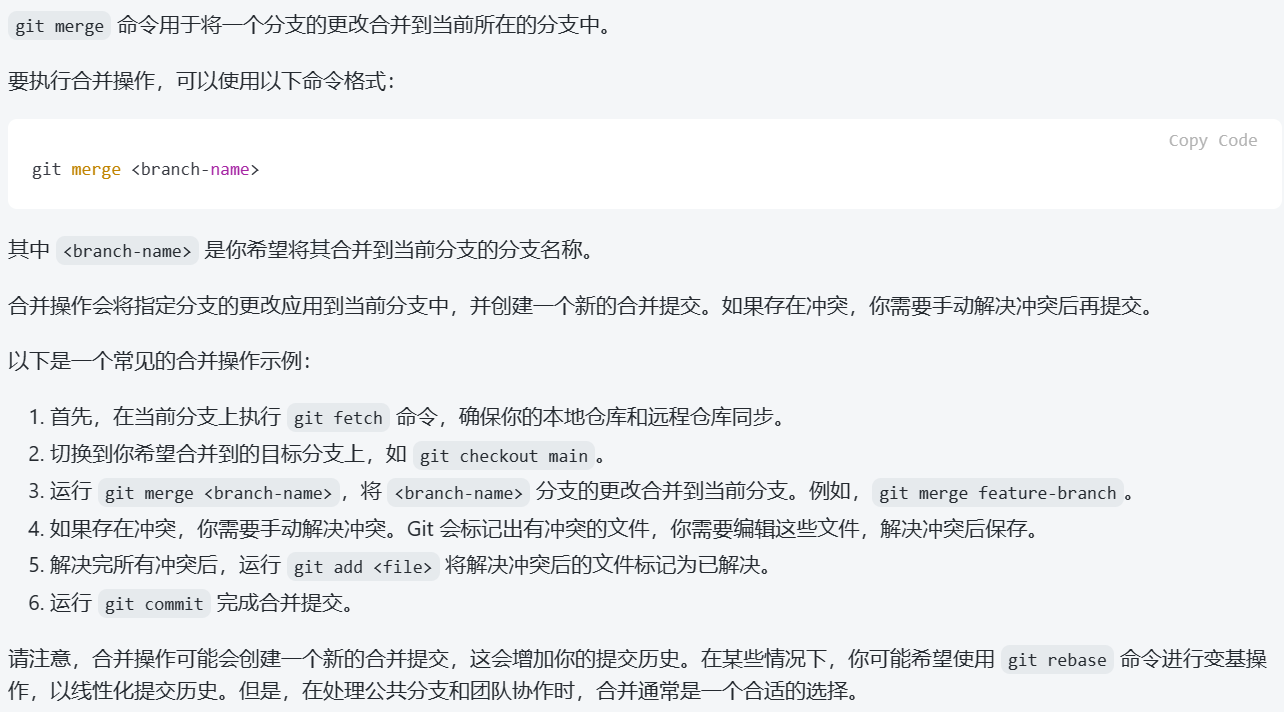
git rebase(内容来源为ChatGPT镜像)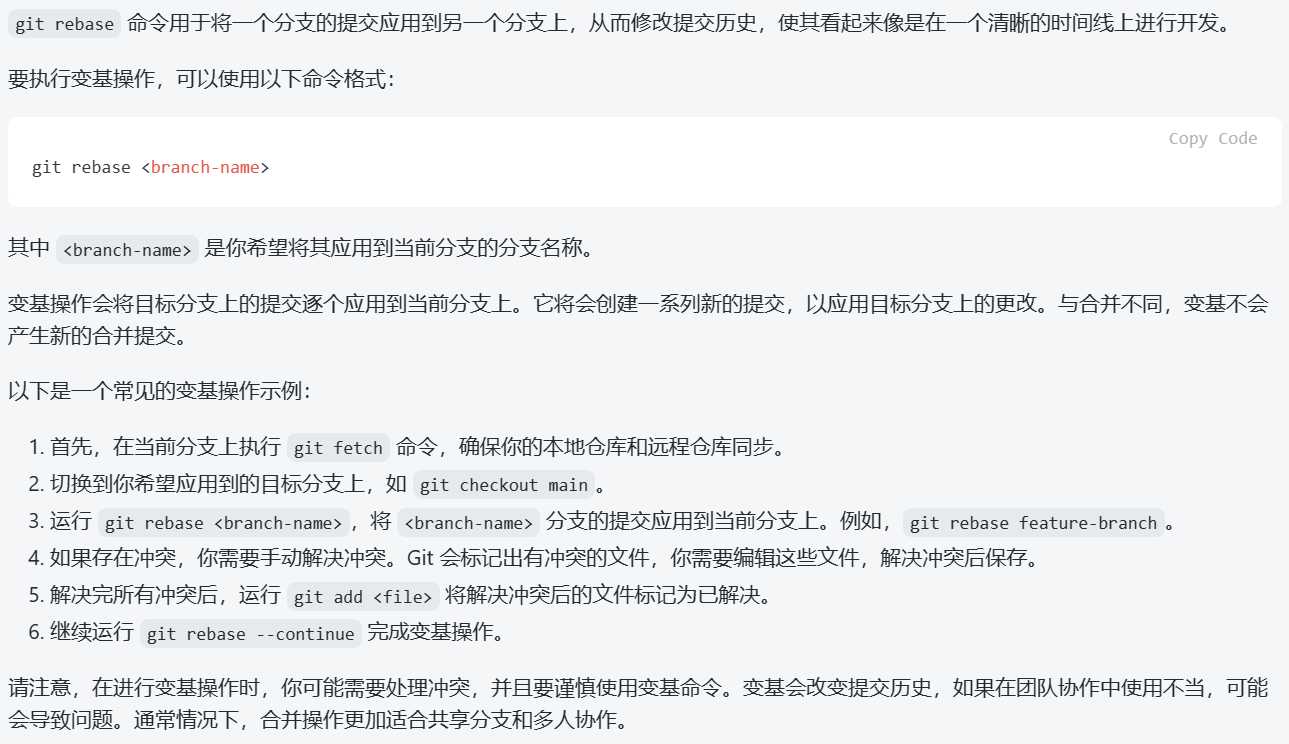
Git Graph – VsCode插件(可视化和便捷管理commit)
基础设置:

Repo:当前文件夹下如果有多个仓库,可以更换Branches:Show All是默认,可以选择只显示某一个或几个分支右侧图标区从左到右为:
检索,终端,设置,fetch,fresh其中,
fetch拉取远程commit,fresh将本页面更新设置最重要的是2个内容:用户设置,自己的信息,自己开发时的个人贡献
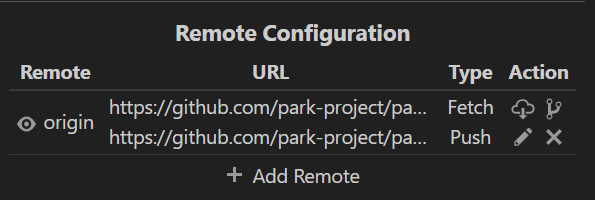
远程配置(如果git clone下来,默认就是fetch和push的仓库相同,可以自主更改)
如何查看分支信息(与Git Graph无关,补充知识)
点击下面的
master(现在默认的主分支已经是main)
在弹出的框中,显示的当前已有的分支,并且可以创建新branch,☁标志是远程,特殊的是
origin/HEAD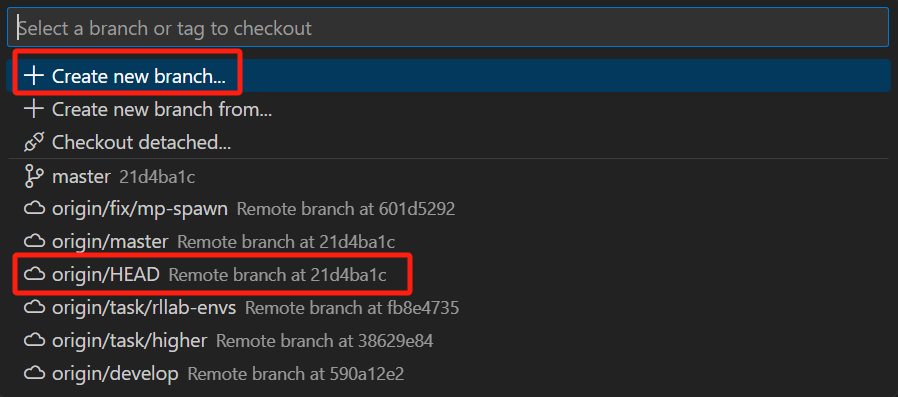
origin/HEAD: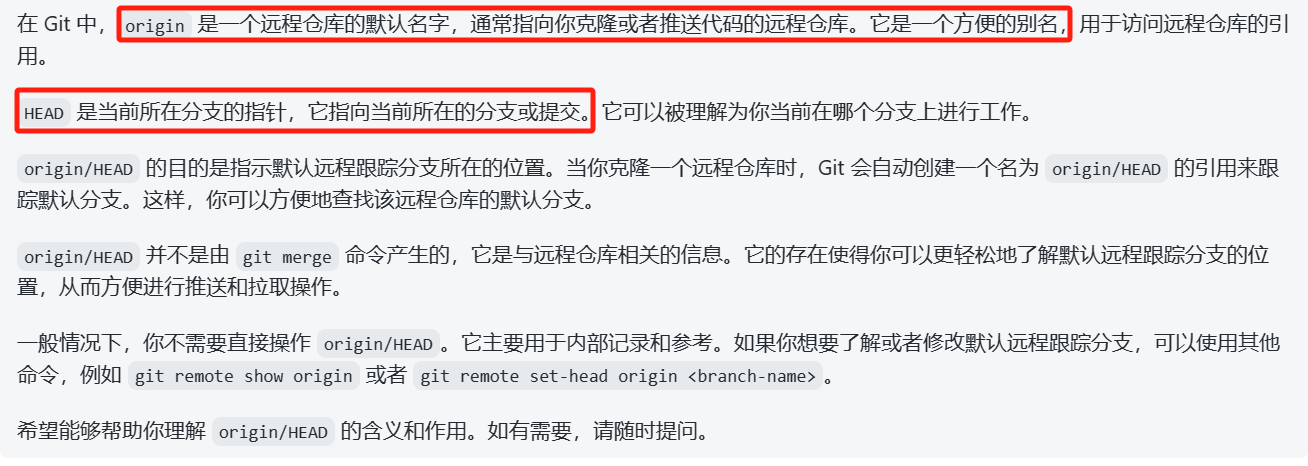
Git Graph查看当前所在commit+分支
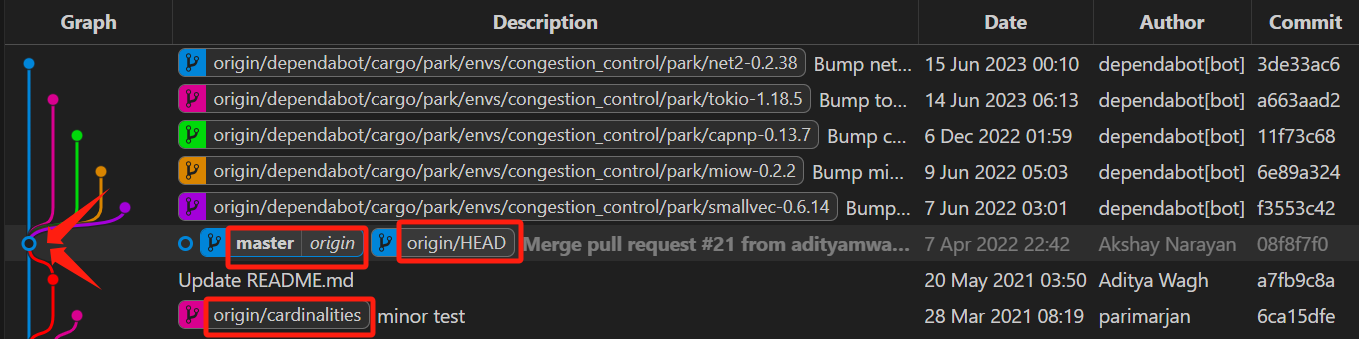
空心圆就是当前所在的commit,对应的branch框中就是当前分支(可以从红色框中内容看出:当前在本地的master分支,master对应分支为远程origin,并且本次commit是
origin/HEAD->这也说明当前所在分支是master,因为origin/HEAD指向当前所在分支/commit)两种branch格式:
- 由
|分割的branch:本地分支|对应远程分支 - 由
/分割的branch:远程仓库/远程分支
- 由
Git Graph实现简便的commit记录间对比和merge
与commit的父节点对比
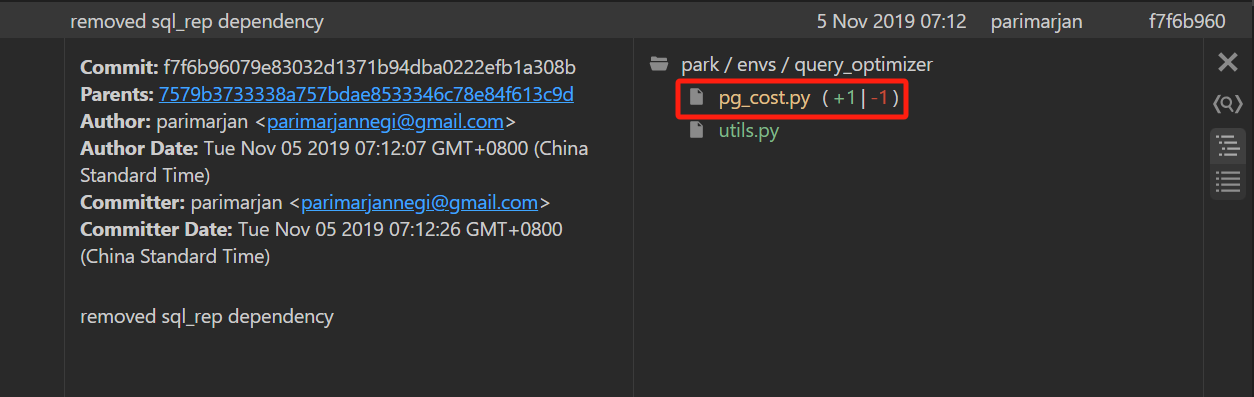
鼠标单击文件名即可查看和父节点commit的增删改(点击后,如下图所示,文件名的括号中
^符号代表父记录)
鼠标悬停在文件名上可以看到更多打开文件的方法
与任意一条commit记录对比
点击一条记录,再找到另一条想对比的记录,按住
Ctrl点击需要对比的记录,在Git Graph中的效果为:(红框内即为对比的两条commit的ID)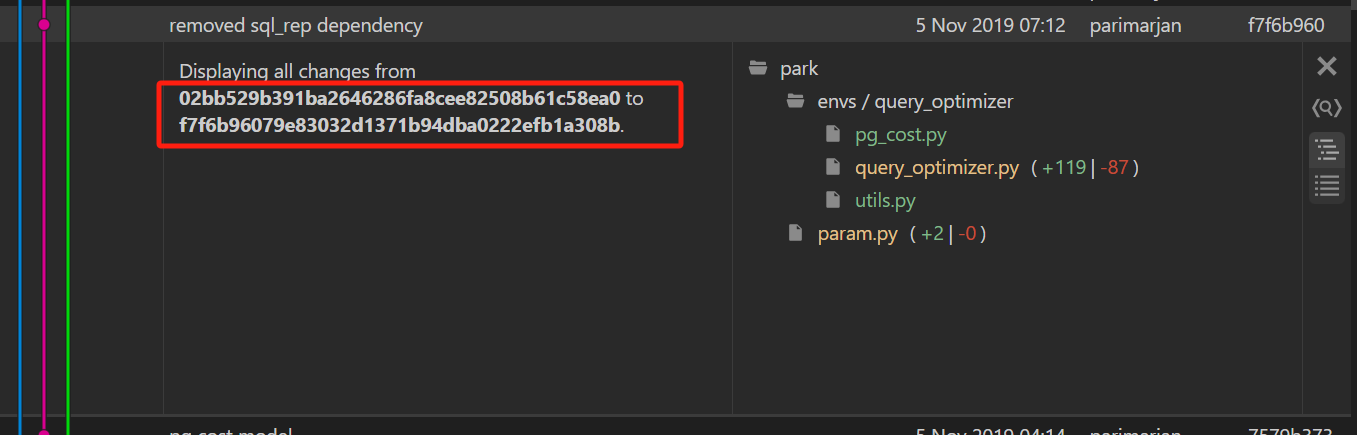
进入
query_optimizer.py文件中,如下图所示,可以从文件名看出确实是这两个ID的文件的对比,右上角的图标点击一下可以自动折叠没有发生更改的代码,专注于更改部分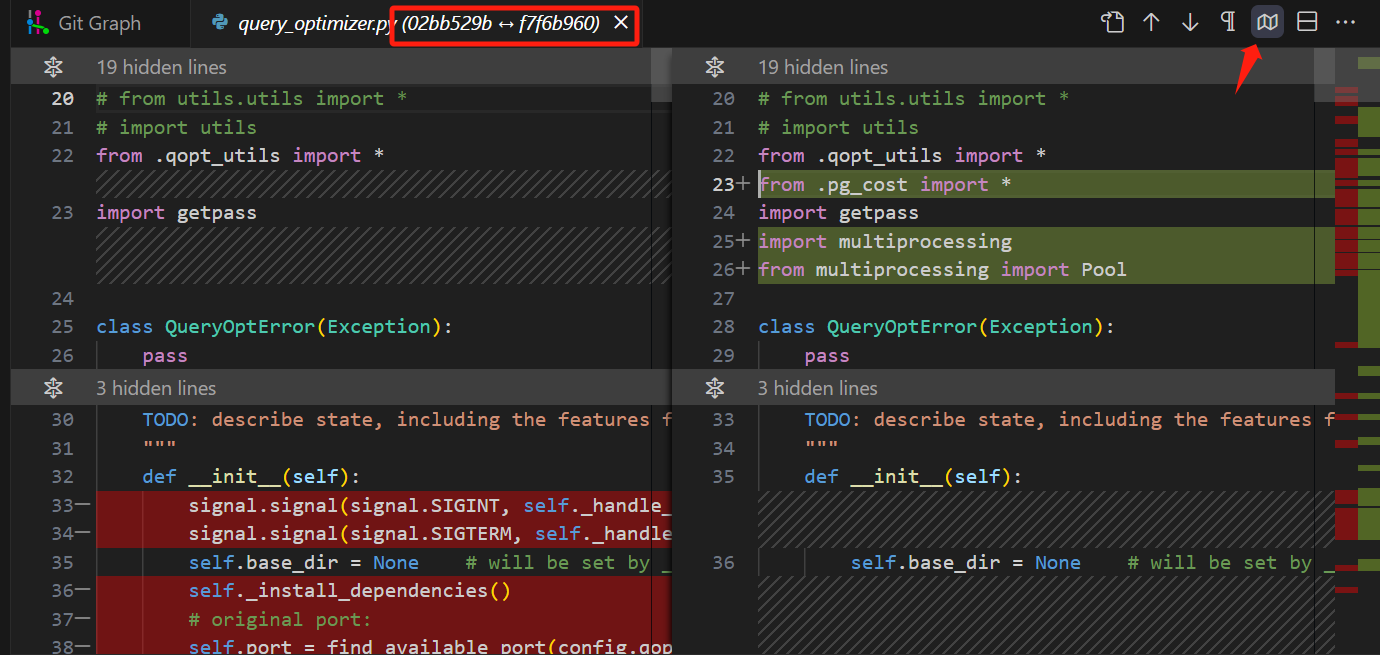
9/30 监控CPU和GPU资源
nvidia-smi pmon: 动态监控GPU显存资源(各项条目如下)

top: 动态监控CPU占用情况
top进入监控后,输入
k(kill的缩写),再Enter,最后输入kill指令的选项(9代表最高级),可以快速杀掉占用最高CPU资源的进程
10/10 shell脚本 day1
脚本具体内容:
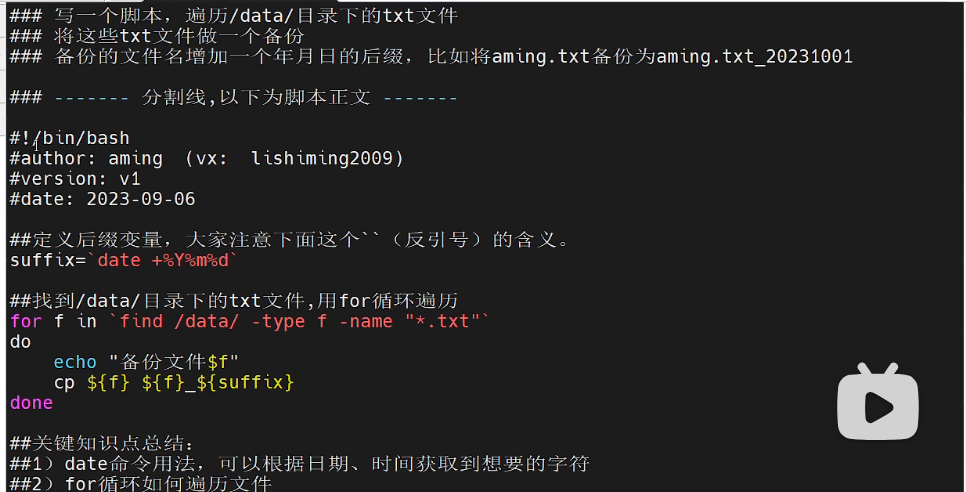
#!/bin/bash的意义:指定命令解释器需要注意的写法
脚本中的反引号:命令替换符号,将命令转化为命令的标准输出,相当于
$()
$variable返回它的值,使用${variable}的情景:
当变量名与其后面的字符产生歧义时。例如,
将被识别为变量
$variable_text,而不是$variable后加上_text。在这种情况下,您可以使用${}来明确变量名的界限:
当需要在变量名称中使用操作符(例如
:,-,+)进行参数扩展时,需要使用${}语法。例如:
2
3
4
5
6
7
8
{var:-default_value}
如果变量定义,则使用变量;否则退出脚本
{var:?error_message}
在变量值前缀或后缀上添加字符串
{var_prefix}text${var_suffix}除了上述情况外,可以直接使用
$符号来引用变量。
if语法:if []是标准,[]内是test条件,需要和[]之间保留空格改进:首先要确定
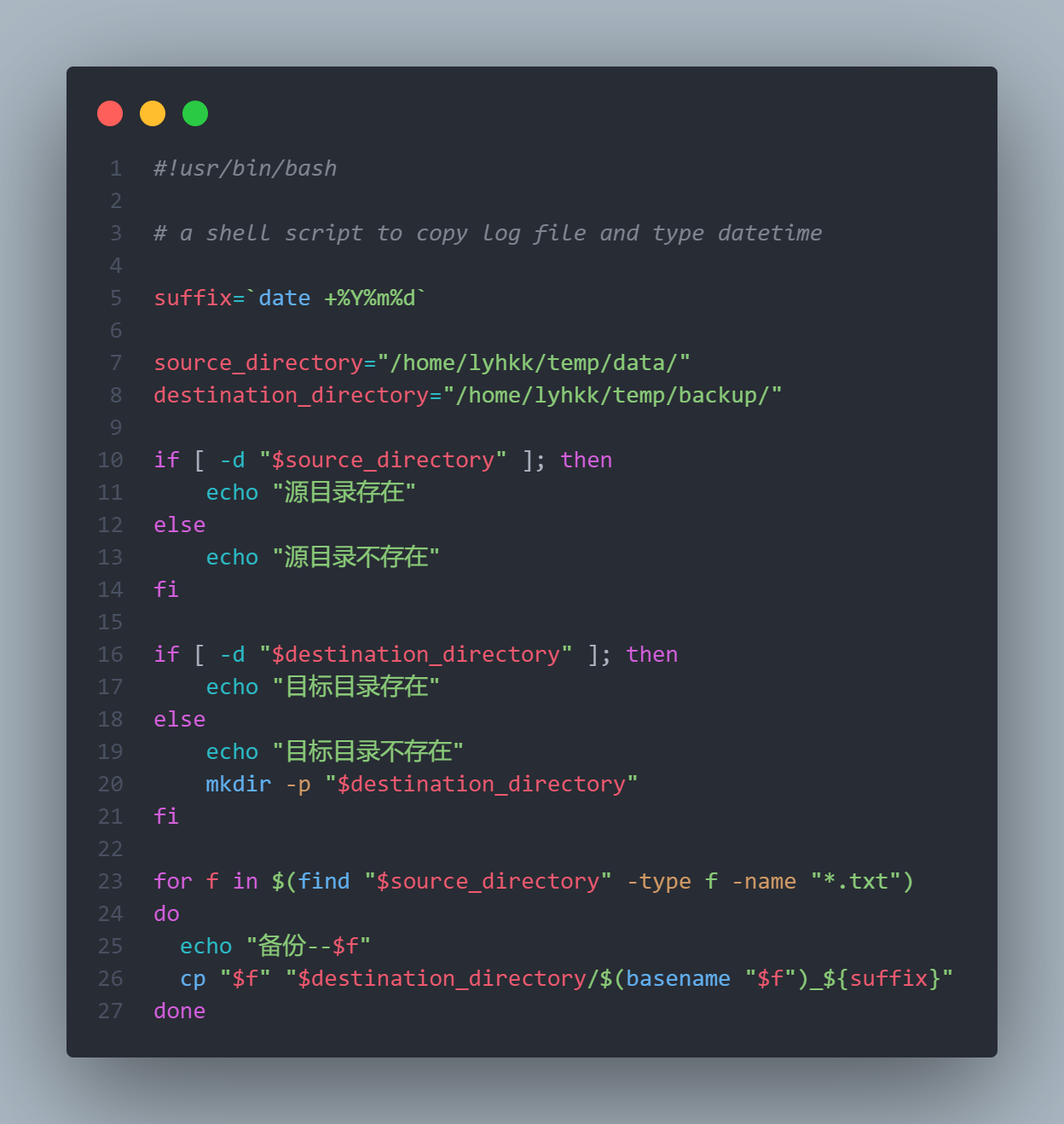
find命令查找的目录存在我自己编写的版本:将
source_directory的文件制作副本,并将副本文件存放在destination_dirextory中
11/27 mv移动多个文件
mv没有-r选项,所以可以用通配符移动多个文件
eg: mv *.txt data/
11/28 less管道
cat filename | less或任何预览一个文件的命令后+ | less可以使用less视图
b: 向上翻页[space]: 向下翻页
12/23 git从远程仓库拉取分支
- 新建一个空文件,文件名为proName(根据项目命名);
手动新建文件夹或命令mkdir proName - 初始化项目
git init - 与远程分支建立关联(远程仓库链接在git上)
git remote add origin git@github.com:xxx/xxx.git - 拉取远程分支至本地
git fetch origin dev(dev为远程仓库的分支名) - 创建本地分支并关联到远程分支
git checkout -b dev(本地分支名) origin/dev(远程分支名)
至此,本地分支dev已与远程分支建立关联,并拉取dev分支项目,
git pull可拉取项目远程所有分支,可通过如下命名查看本地分支及远程分支情况。
git branch 查看本地分支
git branch -a 查看当前所在分支及远程分支
git branch -r 查看远程分支
git branch -vv 查看本地分支与远程分支的关联关系