BEiT V2 architecture
Overall impression: two-stage training
- input image -> visual tokens -> visual presentation (approach: VQ-KD)
- masked image -> visual presentation from stage 1 (approach: MIM)
VQ-KD process(Vector-quantized Knowledge Distillation)
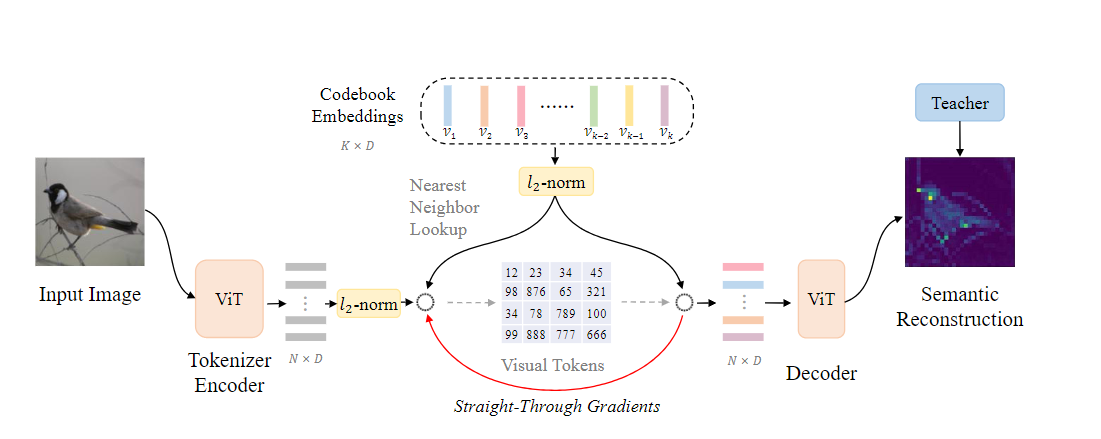
Visual codebook: For a given dataset of visual features extracted from images, we can employ the K-means algorithm to cluster them into several prominent categories. The number of these categories determines the size of the visual codebook, where each category’s centroid represents the specific content of a visual word in the dictionary.
Tokenizer encoder
ViT: encode the image patches and generate eigen vector representations(From the above figure, N for patch number, D for the dimension of vector)
Nearest Neighbor Lookup: employ the L2-norm to regularize encoder output {h
i^p^}i=1^N^ and codebook embeddings {ei^p^}i=1^K^ , then cauculate the minimum cosine distance between them.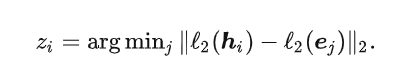
Decoder
Using the nearest neighbor of each image patch as the input of Decoder part. Output is the semantic reconstruction of these visual tokens.
Optimization target(teacher system)
The strategy of VQ-KD involves utilizing the feature learning strategies proposed in model distillation. VQ-KD employs CLIP or DINO as the teacher systems, and utilizes the features generated by the teacher systems as the optimization objective for training the model.
Gradient backpropagation
The arg min function is non-differentiable. In order to backpropagate gradients to the encoder, VQ-KD adopts the approach proposed in VQ-VAE which directly copies the gradients from the decoder’s input to the encoder’s output (indicated by the red arrow in Figure 1), as their optimization directions align.
BEiT V2 pretrain(MIM) -> copy from blog
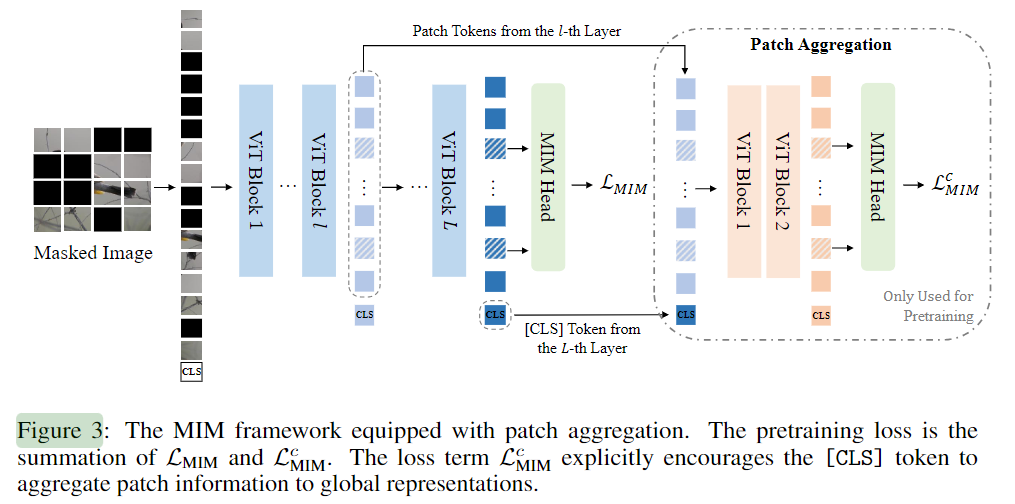
MIM
[CLS]token is settled to learn global informationThe left part of
Figure 3is MIM pretraining process.
[CLS]pretrain