note reference 2: Self-supervised learning
Self-supervised learning
- Overall impression: unsupervised pretraining and supervised fine-tuning
- Goals: The objective is to acquire a set of general feature representations during the pretraining phase, which can be further refined through the utilization of numerous labeled datasets in the downstream task.
- Masked Image Modeling (MIM) methods are proposed for self*-*supervised visual representation learning
BEiT: BERT Pre-Training of Image Transformers
BEiT Architecture:
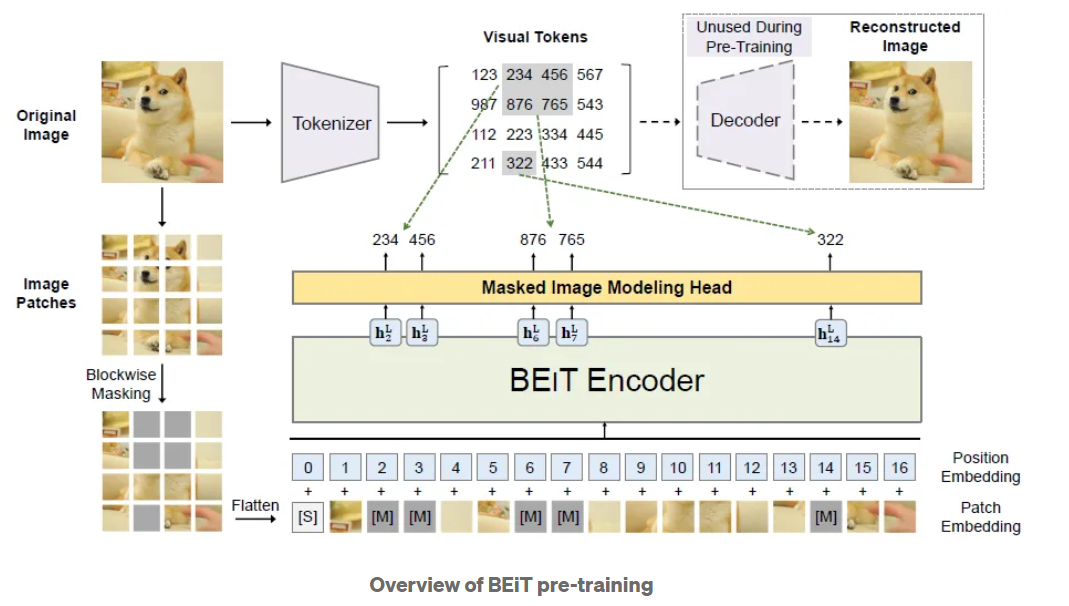
Overall Approach
Pre-training task:
MIM(Masked Image Modeling) -> inspired byBERTDuring pre-training, some proportion of image patches are randomly masked, and fed the corrupted input to Transformer. The model learns to recover the visual tokens of the original image, instead of the raw pixels of masked patches.
MIMuses two views of each image- image patches
- visual tokens
The input of BEiT: The image is split into a grid of patches that are the input representation of backbone Transformer
The approach to tokenize an image: latent codes of discrete VAE(VAE is from DALL·E)
The goal of pretraining: reinforce the model’s capacity to capture generic visual features.
Introduction of two image representations
Image patches

The 2D image of the size H×W×C is split into a sequence of patches of size P2, while the number of patch is N=HW/P2 patches
image -> patches
The image patches xp are flattened into vectors and are linearly projected which is similar to word embeddings in BERT
patches -> patch embeddings
Visual tokens
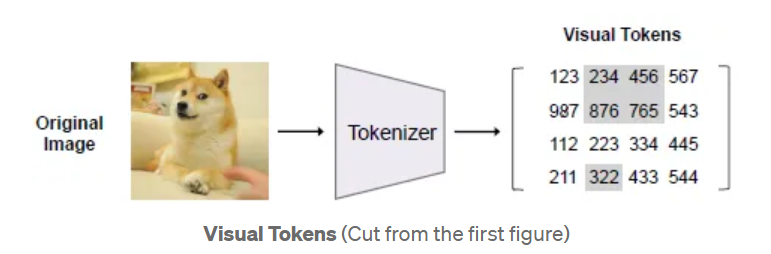
The original image is represented as a sequence of tokens obtained by an image tokenizer, instead of raw pixels
visual tokens are discreate token indices, and the true patches can be refered respectively by the token indices and a visual codebook
The image tokenizer learned by discreate variational autoencoder(dVAE), by DALL·E, is directly used.
Learning process:
By two modules tokenizer and decoder

visual codebook contains eigen vectors that represent various image patches.
ViT Backbone
Following ViT, Transformer backbone network is used
ViTBase is used, which is a 12-layer Transformer with 768 hidden size, and 12 attention heads. The intermediate size of feed-forward networks is 3072.
The fomula and architecture are shown below:

BEiT Pretraning
MIM
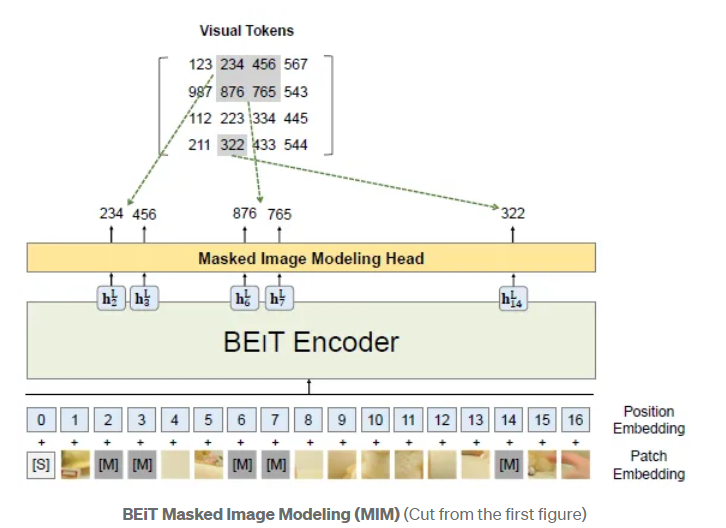
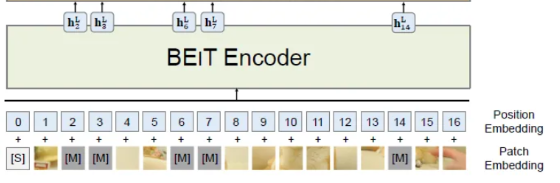
As described above, approximately 40% image patches are randomly masked, where the masked patches are denoted as M. The masked patches are replaced with a learnable embedding e[M].
After a L-layer Transformer, a softmax classifier is used to predict corresponding visual tokens
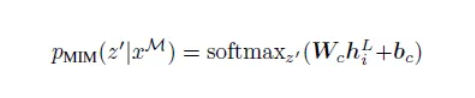
pre-training objective: maximize the log-likelihood of the correct visual tokens zi given the corrupted image
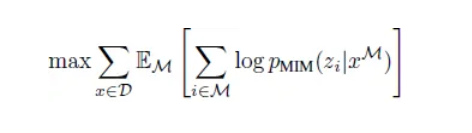
Blockwise Masking

Why dVAE beats VAE

VAE: directly using pixel-level auto-encoding(continuous vector space to represent latent space) -> foucus on short-range dependencies and high-frequency details
dVAE: discrete visual tokens