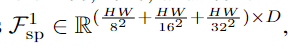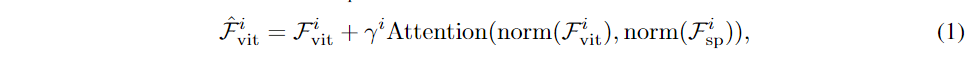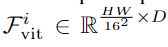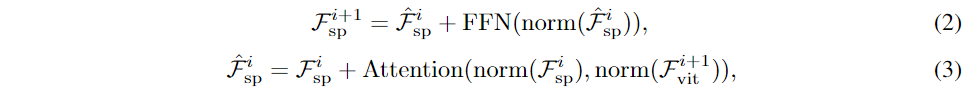ViT Adapter网络结构学习
Overview
本论文提出的ViT Adapter是用在
Dense prediction task上的,包括语义分割、实例分割等像素级预测的任务与Plain ViT的对比:
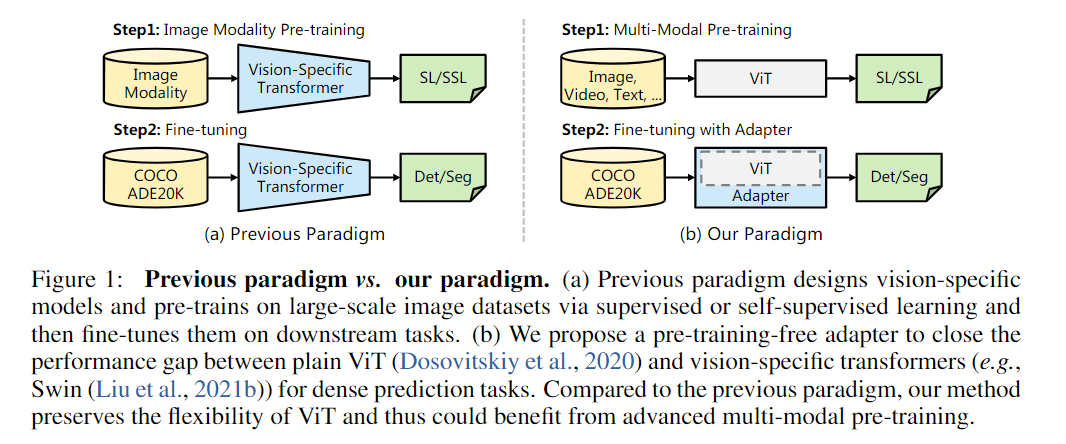
对比plain ViT,使用多模态的数据集预训练backbone,应用到下游任务时,选用合适的Adapter去微调
Architecture
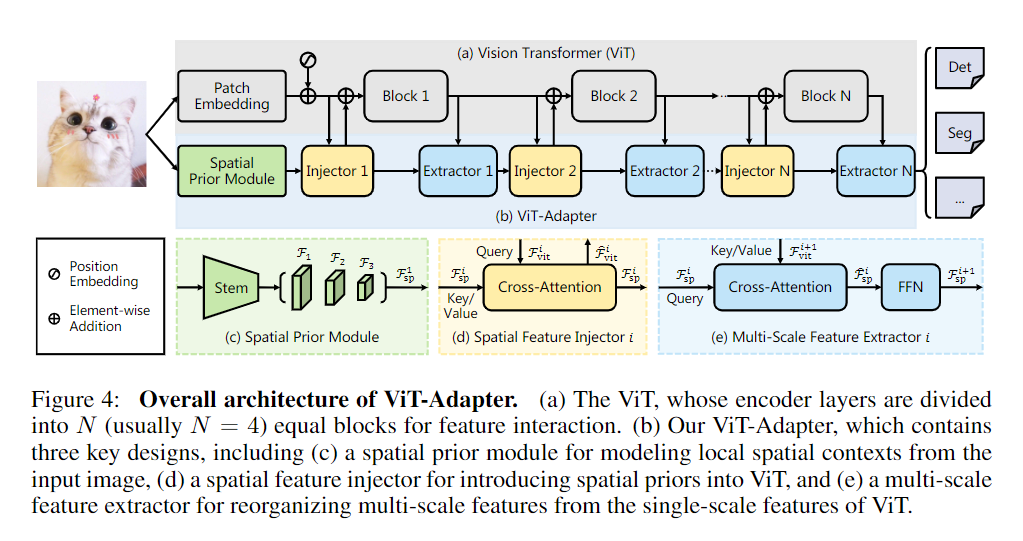
(a) ViT: 相当于没有MLP Head的Plain ViT
(b) ViT-Adapter: 包括(c) (d) (e)三个部分,主要职责是产生多尺度的特征表示,解决了Plain ViT产生单尺度、低分辨率特征图的问题,更适合Dense prediction task
(c) Spatial Prior Module:
model local spatial contexts from the input image(对原始输入图像的空间上下文信息建模)
这个module和ViT的
Patch Embedding是平行的,先通过stem(3个卷积层和一个最大池化层组成,其中,第一个卷积层使得图像分辨率/2, 通道数由3变为inplane;最大池化层让分辨率/2),再通过3个卷积层(每个都是分辨率/2,通道数×2) -> 产生了1/8, 1/16, 1/32三个分辨率的特征图,再将3个尺度1/8, 1/16, 1/32的特征图映射到D-dimension,flatten(特征图->向量) & concat ->D-dimensional spatial feature token(如下图Fsp^1^)
输出:具有多尺度的空间特征
(d) Spatial Feature Injector: (Fviti代表即将输入到ViT的Block i的特征)
顾名思义,将先验的空间特征”注射”给ViT的第i个block的输入,通过
Cross-Attention机制交互->获得多尺度空间信息数学表示:
假设输入分patch时分为16×16个patch
γ是可学习向量∈RD,用来平衡ViT第 i block的输入和
Cross-Attention之后的输出(e) Multi-Scale Feature Extractor:
基于ViT第i个Blcok输出的单尺度特征(记为Fviti+1),重组(reorganize)多尺度的空间特征(Fspi -> Fspi+1)
数学表示:
与Injector不同的是,进入
Cross-Attention的query和(key,value)的角色互换了,因为Injector是依据Fspi (作为key和value)产生Fviti(query),Extractor是依据Fviti+1(key,value)产生Fspi+1(Fspi为query)FFN是Feed-Forward Network(前馈神经网络),实现ViT Adapter多用
Conv FFN,增强非线性表达能力(Attention是矩阵乘法,是线性变化)