V1 V2模型对比:
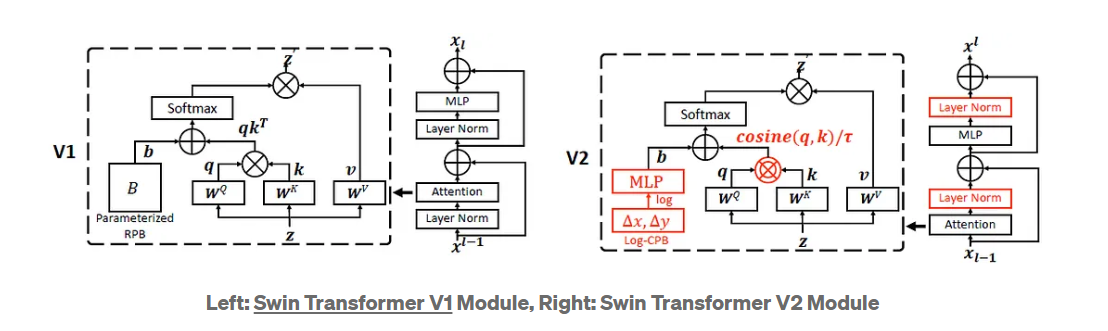
Residual-post-norm Method
好处:增强训练的稳定性
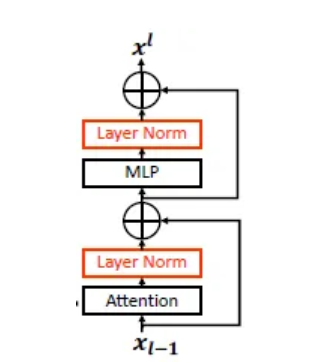
Swin V2中的residual-post-norm
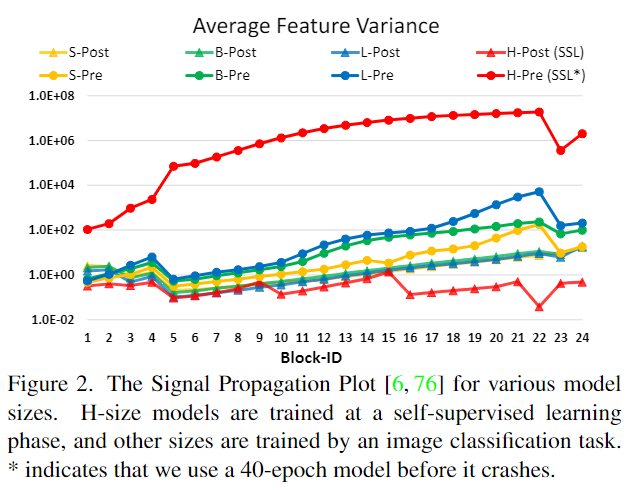
训练更稳定的实验数据依托:
Pre方法:Swin V1使用的normalization策略
Post方法:Swin V2使用的normalization策略
Figure 2应该从两个角度看:
- 先看Pre方法下(节点用’●’表示),随着模型规模增大,层数增加,输出值不断累加,深层输出和浅层输出幅值差很多,导致训练过程不稳定
- 再看同一数据规模下(同一颜色的线条),Pre方法的activation amplitudes更小,故训练更稳定
Scaled Cosine Attention
使用点积的方法计算相关性,一些blocks & heads的attention map会受到小部分的像素对的支配,这个影响在使用residual-post-norm时更为显著(为什么?)
计算pixel i和j之间的相关性:

优势:milder attention value, naturally normalized function
Scaling Up Window Resolution
原始的方法:相对位置编码是[-M+1, M-1],当跨不同窗口大小进行迁移学习时,预训练中学习到的相对位置偏差矩阵用于通过双三次插值来初始化微调时的偏差矩阵(windw size不同)。
CPB:通过两层MLP,取代双三次插值,因为用到了可学习的网络,更灵活,用于迁移学习更优
Log-Spaced CPB(CPB for Continous Positional Bias)
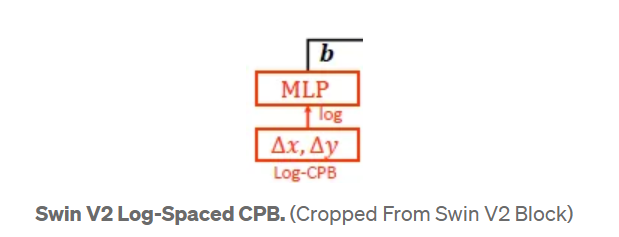
计算公式:
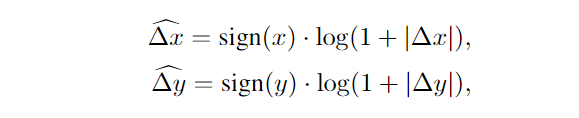
sign()是指出正负号的函数
eg: 当从8×8 window size的预训练模型迁移到16×16 window size时,输入的相对位置偏移量的区间(input coordinate range)从[-7, 7] -> [-15, 15] (V1不使用CPB)
extrapolation ratio(扩率) 不使用CPB (15-7)/7 = 1.14 Log-Spaced CPB ln(7+1)=2.079, ln(15+1)=2.773 (2.773-2.079)/2.079 = 0.33 总结:外扩率减小,Meta network(MLP)的输入维持在比较稳定的区间,保证最后产生的相对位置编码的准确性
SimMIM进行自监督训练(目前不了解)
Ways to save GPU memory
- Zero-Redundancy Optimizer: 将模型参数和相应的optimization states分布到不同GPU上,significantly 节约显存开销
- Activation Check-Pointing: 减少Feature maps存储的开销,但会增长30%训练时间
- Sequential Self-Attention Computation: 取代了基于batch的self-attention预算。这个优化应用在前两个stage,减少显存开销,对训练时间影响小
model variant
