Configure the virtual environment
首先,要确保环境为cuda 11.0,cuda版本是为之后
mmcv-full 1.3.0(包含所有的特性以及丰富的开箱即用的CPU 和CUDA 算子)安装做准备。显卡驱动版本要支持这个cuda版本(笔者使用腾讯云 V100 GPU云服务器,下图是GPU驱动和cuda版本)
conda create创建一个Python 3.8的虚拟环境,也是为mmcv-full安装做准备pip install torch=1.7.1+cu110:这是最优解,但一开始没有意识到,之后会详细解释。所以我的第二步是进入unlim/beit目录下pip install -r requirements.txt根据
unlim/beit/semantic_segmentation/README.md的tutor安装mmcv-full, mmseg, timm, apex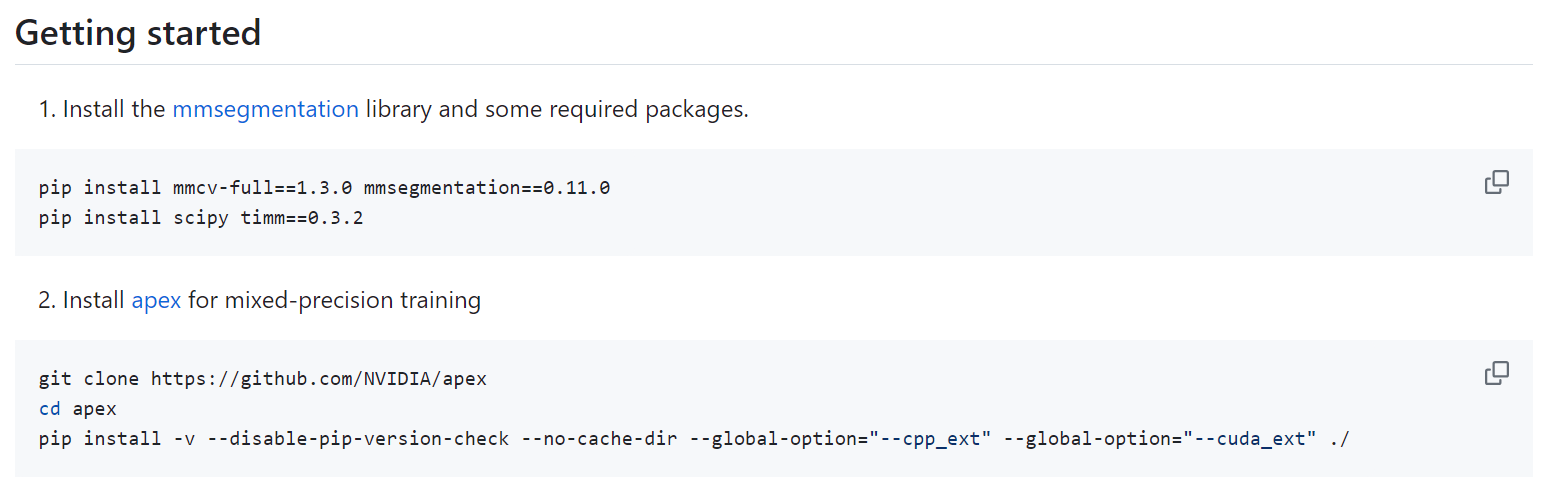
但这里安装到apex就出错了,由于pip在之前创建虚拟环境时已经更新至最新版
23.2.1,--global-option has already been deprecated,并且显示packaging模块找不到。此时去Nvidia的apex官方仓库,找到了新的命令:1
2
3
4
5
6
7
8git clone https://github.com/NVIDIA/apex
cd apex
# if pip >= 23.1 (ref: https://pip.pypa.io/en/stable/news/#v23-1) which supports multiple `--config-settings` with the same key...
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./
# otherwise
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --global-option="--cpp_ext" --global-option="--cuda_ext"
# only python
pip install -v --disable-pip-version-check --no-build-isolation --no-cache-dir ./按照第一个命令,安装后import apex仍然会报错:
AttributeError: module 'torch.distributed' has no attribute '_all_gather_base',这是因为torch版本低,但是torch==1.7.1是实验要求不可更改,根据github apexissue 1532,要去找branch里的老版本apex –>apex-22.04-dev再安装apex,又比较奇怪,这个版本的apex不支持
--config-settings,但使用--global-option对应的命令是可以安装完整版的(cuda+cpp+python),也不会报错packaging module not foundpackaging module not found这个报错在
issue 1679中讨论到了,并有pull request 1680,解决方案是在pyproject.toml中修改: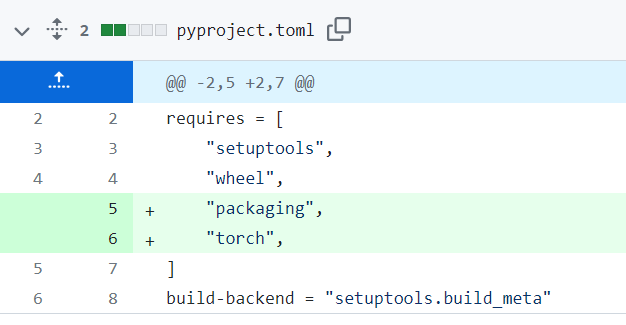
以我之前安装的步骤,这样修改完,再安装apex,会报
torch not found,我没有详细论证,但推测和torch 1.7.1有关,这也是接下来要说的安装仍然有一个报错,就是关于torch的,因为
torch.version.cuda的版本(10.2)和真正使用的cuda版本(11.0)不同,所以需要安装对应cuda版本的torch,我的方法是去pytorch官方下载对应的.whl包,并pip安装,之后就可以安装了接下来就是比较常规的内容:
- 将
beit/semantic_segmentation/mmcv_custom添加到环境变量,或者直接复制到对应虚拟环境的site_packages文件夹下,这是因为mmcv_custom调用apex,实现了['IterBasedRunnerAmp','LayerDecayOptimizerConstructor', 'SETR_Resize', 'DistOptimizerHook', 'train_segmentor']这些训练用的组件 - 还有就是将
mmseg/core/evaluation/metrics.py中的np.float改为float,因为不再支持np.float
- 将
参数:batch size(samples_per_gpu) = 4,workers = 8,占用显存达到98%
目前仍待解决的问题:(北京时间 8/20 9:50 更新)
直接运行报错
Invoked 'with amp.scale_loss', but internal Amp state has not been initialized,根据apex官方给出的文档,,apex只需要三行代码就可以优雅地调用Amp
我们在
mmcv_custom/tran_api.py找到了初始化的实现:这里有一个疑惑,为什么cfg.optimizer_config.get("use_fp16", False)下还要初始化Amp为混合精度(根据官方文档,opt_level="O1"即为混合精度,而正因为use_fp16==True,才成为混合精度(乘法用fp16,加法用fp32,混合精度的好处是可使显存,训练时间大幅减少,但不明显损害训练精度),这一点目前没搞懂。并且,从现有的10000 iterations看,训练过程中震荡很明显,速度很慢(160k iters训练预计使用4 days),batch size也只能开到4(
32G显存 单卡),并不像真正使用了Amp加速训练,这也引出了第二个问题1
2
3
4
5
6
7
8# use apex fp16 optimizer
if cfg.optimizer_config.get("type", None) and cfg.optimizer_config["type"] == "DistOptimizerHook":
if cfg.optimizer_config.get("use_fp16", False):
model, optimizer = apex.amp.initialize(
model.cuda(), optimizer, opt_level="O1")
for m in model.modules():
if hasattr(m, "fp16_enabled"):
m.fp16_enabled = True本实验是否真的能通过单GPU训练达到复现,因为apex工具包的内容全部关于分布式训练,而分布式训练核心在于将不同计算核心开不同的进程,增大并行量,单GPU使用分布式训练(目前我实验使用的方法,因为我感觉代码,尤其是mmcv_custom不容易与分布式训练脱钩)。使用
ps aux命令查看进程信息:

可以看出与多进程相关的任务很多,但真正在服务于训练的只有
PID 32444的进程,所以分布式训练可能很难真正起作用,因为计算核心只有一个包括即使修复了第一个问题,可以使用混合精度,是否会真正性能提升也是未知数
解决未使用fp16的问题:(8/20 14:28更新)
之前运行
dist_train.sh脚本,总提示1
RuntimeError: Invoked 'with amp.scale_loss', but internal Amp state has not been initialized. model, optimizer = amp.initialize(model, optimizer, opt_level=...) must be called before with `amp.scale_loss`.
这个报错表示:model和optimizer这两个internal Amp state初始化必须在
with amp.scale_loss之前。而with amp.scale_loss的调用在site-packages文件夹下mmseg/apis/train.py的train_segmentor类中。故我们一定要修改它,mmcv_custom(mmcv_custom提供了一系列在本次实验中适用的api)中,我们找到了适合的train_segmentor类1
2
3
4
5
6
7
8
9
10
11
12'''
1. 将`optimizer = build_optimizer(model, cfg.optimizer)`放在`if distributed:`之前
2. 将初始化Amp state写在optimizer创建和`if distributed:`之间
'''
# use apex fp16 optimizer
if cfg.optimizer_config.get("type", None) and cfg.optimizer_config["type"] == "DistOptimizerHook":
if cfg.optimizer_config.get("use_fp16", False): # False没懂
model, optimizer = apex.amp.initialize(
model.cuda(), optimizer, opt_level="O1")
for m in model.modules():
if hasattr(m, "fp16_enabled"):
m.fp16_enabled = True在
mmseg/apis/train.py中,我写成了:(因为只要分布式训练,我就用amp)1
2
3
4
5
6
7
8
9
10
11
12optimizer = build_optimizer(model, cfg.optimizer)
# put model on gpus
if distributed:
find_unused_parameters = cfg.get('find_unused_parameters', False)
# Sets the `find_unused_parameters` parameter in
# torch.nn.parallel.DistributedDataParallel
model, optimizer = apex.amp.initialize(model.cuda(), optimizer, opt_level="O1")
model = MMDistributedDataParallel(
model.cuda(),
device_ids=[torch.cuda.current_device()],
broadcast_buffers=False,
find_unused_parameters=find_unused_parameters)结果:训练时间缩短为一半,但部分loss出现梯度溢出的情况,且显存消耗依然很大,仍有很多需改进的部分
最开始训练时梯度溢出->推测是: 一开始loss本身过大
网上常见的梯度溢出的可能:
mask_fill使用-1e9 mask的问题- softmax的溢出
- sum函数的溢出
为什么我不认为我的是这些常见问题之一:因为这个model的实现没有真正用到fp16,而是一直在用fp32,只有optimizer使用到了fp16,这也是为什么显存始终占用98%,baych size无法提升
解决无法validation的问题:
IterBasedRunnerAmp是现用的runner,按照mmcv_custom的写法,它将被注册到mmcv的registry类当中,但在mmseg的apis/train.py的第110行左右,内容是eval_cfg['by_epoch'] = cfg.runner['type'] != 'IterBasedRunner',在这里,IterBaseRunnerAmp并不会被识别为IterBasedRunner,尽管实际上它是。所以,这里我直接改成了eval_cfg['by_epoch'] = Falsevalidation之后显存不足 -> new issue -> 目前先把validation设为
160000iterations做一次,打算先花2天跑完 Training,只看最后的validation结果
Results

差距主要由于batch size(我是4 batchs/GPU * 1 GPU,github是2 batchs/GPU * 8 GPUs)
1 | +---------------------+-------+-------+ |